1章 手続きによる抽象化
計算プロセスについて勉強しよう。計算プロセスとはコンピュータの中にある抽象的な概念だ。プロセスは評価される際に別の抽象概念であるデータを操作し、その評価のされ方はプログラムと呼ばれるルールのパターンによって定められる。人々はプロセスに支持するためにプログラムを作るのだ。つまり、魔法をかけてのコンピュータの妖精を呼び出してやるのだ。
計算プロセスは魔法使いが思う妖精と実によく似ている。見ることも触ることもできない。物質で構成されているのですらない。しかし確かに実在し、色々と知的な仕事をしてくれる。質問に答えてくれるし、銀行で支払をしたり、工場でロボットの腕を動かしたりして現実の世界に影響を与えている。魔法使いが呪文をかけて妖精を操るように、我々はプログラムを使ってプロセスを操るのだ。神秘的プログラミング言語で注意深く書かれた式で、プロセスの仕事を指示するのだ。
まともに動作するコンピュータ上では、計算プロセスはプログラムを正確に実行する。魔法使いの弟子のように、初心者プログラマはプログラムを実行した結果を理解し、予期できるように勉強しなくてはならない。ほんの小さなエラー(バグとかgitcheとか呼ばれる)でさえ、複雑で予測できない結果をもたらすことがあるのだ。
幸運なことにプログラムの勉強は魔法の勉強よりかなり安全だ。我々の扱う妖精は画面の向こう側にいる。ただ現実世界に関係するプログラミングには注意や、経験や、知恵が必要だ。たとえば、CADプログラムの小さなバグが飛行機の墜落や、ダムの崩壊や、ロボットの自爆といった大惨事を引き起こす可能性がある。
名人級のソフトウェア技術者になると、プログラムを整理し、プロセスがどのように振舞うかをかなり正確に予測できる。あらかじめシステムを心に描くことができるから、大惨事にならないプログラムの組み立て方をしっている。もし問題が起きたら、プログラムをデバッグすることができる。良い設計のシステムは良い設計の自動車・原子炉と同じようにモジュール化された設計になっていて、個々のパーツを作り、取り換え、分割してデバッグできる。
Lispでプログラミング
プロセスを記述のに手頃な言語が必要だ。ここではLispを使う。日常的な思考が英語・フランス語・日本語といった自然言語で表現されるように、定量的現象(?訳注:quantitative phenomena)が数学的な表記法で表現されるように、我々の手続き的な思考はLispで表される。Lispは1950年代の後半にある論理式の使用について推論するため発明された。その論理式は再帰方程式といい、コンピュータの計算モデルのひとつである。この言語はJohn McCarthyによって構想され、彼の論文「Recursive Functions of Symbolic Expressions and Their Computation by Machine」(McCarthy 1960)が基になっている。
はじめ数学的なものとして開発されたにもかかわらず、Lispは実用的なプログラミング言語だ。LispインタプリタとはLispで記述されたプロセスを実行するマシンである。最初のLispインタプリタはMcCarthyが、MIT Research Laboratory of ElectronicsとMIT Computation Centerの同僚や学生の協力を受けながら実装した。(*1) Lisp(LISt Processingの頭文字となっている)は微分積分などの代数式に記号的にアタックするために設計された。そのため、アトムやリストといった新しいデータの概念を含んでいたが、これはこの時代の他の言語と著しく異なるものだった。
Lispは人々が協調して設計した言語ではない。ユーザの要求と実装上の都合によりその都度実験的に改良され、テキトーに発展していったのだ。(訳注:そのため様々な実装が生まれては消えていった。)そのくだけた発展は長い間続けられ、Lispのユーザ達は伝統的に、「Lispのオフィシャルな規格を定義しよう」といった流れに反対してきた。このような経緯と、初期からの柔軟で優雅な考え方により、今日でもさまざまな分野で使われているものとしては2番目に古い言語であるLispに、頻繁に最新のプログラム設計のアイデアを含ませ調和させることができるのだ(ちなみに1番古いのはFortran)。そのためLispと言う名前は今日ではたくさんある方言のファミリーを表し、それぞれは初期の特徴を共有しながらも、重要な部分でさえ異なっている場合がある。本書ではSchemeというLisp方言を使う。(*2)
その実験的な性格と記号操作の重視のせいで、初期のLispは数値計算ではかなり遅かった、少なくともFortranと比較すると。しかし何年もして、Lispのコンパイラが開発されプログラムをマシンコードに変換できるようになると数値計算もなかなか効率的に実行できるようになった。また特別なアプリケーションで使われると、Lispはすばらしい効果を発揮した。(*3) Lispは絶望的に遅いという古い評判を克服できずにいるが(訳注:2009年現在ではCの次ぐらいに速いと言われています)、現在では速度を主な懸案事項としない多くのアプリケーションで使われている。
Lispが主流の言語じゃないとして、じゃあ何でそれをプログラミングの議論の骨組みとしてつかうんだろう?なぜなら重要なプログラムの構築と、データ構造と、それらをサポートする言語的な機能を勉強するのに優れた媒体となるユニークな機能がLispにはあるからだ。その中でももっとも重要なのはプロシージャや手続きと呼ばれる機能である。これによりLisp自身をデータとして表現し、操作することができる。この伝統的な「受動的」なデータと「能動的」なプロセスとの境を曖昧にする技法により強力なプログラムテクニックが使えるようになる。後で分かるようにLispのプロシージャをデータとして扱う柔軟性はこれらのテクニックを探求する上でLispをもっとも便利な言語にしている。またプロシージャをデータとして扱うことはインタプリタやコンパイラなど他のプログラムをデータとして扱うときにとても優れている。そしてそれより何より、Lispでプログラミングするのはとても楽しいのだ。
1.1 プログラムの要素
強力なプログラミング言語はコンピュータにタスクを指示するだけでなく、プロセスに関する考え方を整理するのに役立つフレームワークにもなる。言語について説明する時、シンプルな考えを複雑なものにまとめていく過程で言語が提供する手段に注目すべきだ。どの強力な言語も3つのメカニズムを備えている。
- プリミティブ(単純)な式 言語と関係する最もシンプルな要素。
- 組み合わせ方 シンプルな要素を組み合わせてもっと複雑なものをつくる。
- 抽象化のやり方 シンプルな要素を組み合わせて名前を付け、ユニットで扱えるようにする。
プログラミングで、我々は2種類の要素を扱う。プロシージャとデータだ。(この2つは実はそんなに違わない) 簡単に言うと、データは我々が操作したいものであり、プロシージャはデータを扱う時のルールを記述したものだ。それで、強力なプログラミング言語はプリミティブなデータとプリミティブなプロシージャを表現できて、プロシージャとデータを組み合わせ、抽象化できるようにする必要がある。
この章ではシンプルな数値のデータのみを扱い、プロシージャを構築するルールに注目していく。(*4) 後の章で同じルールがもっと複雑なデータを操作するプロシージャを作る時にも同じように使えることが分かる。
1.1.1 式
プログラミングを始める簡単な方法のひとつは対話的インターフェースを使うことだ。Schemeインタプリタを使ってみる。コンピュータ端末の前に座っていることを創造してみよう。あなたが式をタイプすると、インタプリタはその式を評価した結果をディスプレイに表示する。
1つのプリミティブな式を入力してみる。数字だ。(正確には10進数の整数)Lispにこう入力すると、
> 486こう返ってくる
486数字はプリミティブなプロシージャ(+とか*とか)と組み合わせて別の新しい式を作り、数字にプロシージャを作用させることができる。たとえば
> (+ 137 349)
486
> (- 1000 334)
666
> (* 5 99)
495
> (/ 10 5)
2
> (+ 2.7 10)
12.7上記のように、式のリストをかっこで区切ってプロシージャの適用範囲を示す式のことをコンビネーション(組み合わせ)という。そのリストの左端の要素をオペレータといい、他の要素をオペランドという。コンビネーションの値はオペレータに指定したプロシージャにオペランドの値を引数として与えた結果となる。
オペレータをオペランドの左側に置く記法を前置記法あるいはポーランド記法という。最初は数学の慣習的な表記法との違いに戸惑うかもしれない。しかし前置記法にはいくつか利点がある。ひとつはプロシージャに好きな数の引数を与えることができることだ。以下に示すように
> (+ 21 35 12 7)
75
> (* 25 4 12)
1200曖昧さは発生しない。オペレータは常に左端の要素だし、コンビネーションはかっこで囲まれている。
2つ目の前置記法の利点は自明な方法で拡張できることだ。つまりコンビネーションをネストさせることができる。コンビネーションの要素はそれ自身がコンビネーションなのだ。
> (+ (* 3 5) (- 10 6))
19Lispインタプリタが評価できるネストの深さや式の複雑さに限界はない。(原理上は) 我々人間は次のような比較的シンプルな式でも混乱するが
(+ (* 3 (+ (* 2 4) (+ 3 5))) (+ (- 10 7) 6))コンピュータは簡単に57と評価することができる。我々は次のように式を書くことで
(+ (* 3
(+ (* 2 4)
(+ 3 5)))
(+ (- 10 7)
6))このフォーマットはプリティープリントとして知られている、長いコンビネーションのオペランドを水平に整列させる……を使ってインデントすることで式の構造を明確にできる。(*5)
複雑な式に対しても、インタプリタは同じベーシックな動作を繰り返す。ターミナルから式を読み、式を評価し、結果を表示する。このような方法で動作することを、インタプリタがread-eval-print loop(読み込み-評価-表示のループ)を実行する、という。ここでは明確にインタプリタに値を表示するよう指示する必要がないことに注目してほしい。(*6)
1.1.2 命名と環境
プログラミング言語の重要な側面として、オブジェクトを参照するために名前を与えることが挙げられる。オブジェクトを値とする変数を名前で識別するのだ。
Schemeでは define を使って名づける。
(define size 2)と入力すると、インタプリタは2という値と size という名前を結びつける。一旦結び付けてしまえば2という値を名前で参照できる。
> size
2
> (* 5 size)
10define の使い方をもっと挙げると、
> (define pi 3.14159)
> (define radius 10)
> (* pi (* radius radius))
314.159
> (define circumference (* 2 pi radius))
> circumference
62.8318define はこの言語でもっともシンプルな抽象化の方法だ。これを使えば circumference のように、いくつかの要素を組み合わせた式の結果にシンプルな名前を付けることだってできる。たいてい、オブジェクトはすげえ複雑な構造になっていて、使いたいときにいちいちその詳細を思い出すにはあんまりにも不便だ。そんなわけで、複雑なプログラムはオブジェクトの複雑さを少しずつ増やしていくようにして構築される。インタプリタはこのように少しずつプログラムを構築していく場合に特に便利だ。対話的インターフェースによって、名前とオブジェクトの結びつきを少しずつ作っていくことができるからだ。この機能がLispにおいてアジャイル開発とテストを促進し、プログラムが割と簡単なプロシージャがたくさん集まってできているという証明になっている。
値とシンボルを結びつけて後で取得できるってことは、どこかに名前とオブジェクトのペアを記録するメモリがあるってことだ。そのメモリのことを環境という。(正確には環境っていうのはいくつもあって、この場合はグローバル環境)
1.1.3 コンビネーションの評価
この章の目的のひとつは手続き的な問題を取り上げることだ。ここではコンビネーションを評価する時に、インタプリタもプロシージャというか手続きにしたがっているとする。
- コンビネーションを評価する時、次のようにする。
- 1. コンビネーションの中の部分的な式を評価していく
- 2. 部分式の左端のプロシージャ(オペレータ)に、部分式の他の部分である引数を与えて結果を得る。
このシンプルなルールでもプロセスの一般的に重要な点を示している。1つ目としてコンビネーションを評価するプロセスではその部分式となるコンビネーションを評価しなくてはならないことに気づくだろう。つまり、この評価のルールは再帰的で、ルールの中に自分自身を呼び出すステップが含まれる。
再帰という考え方がいかに簡潔に式を表現できるかに注目してほしい。深くネストしたコンビネーションを他の方法で表現しようとすると、かなり複雑なプロセスになる。というわけで簡潔に表現できる例をあげる。例えば、
(* (+ 2 (* 4 6))
(+ 3 5 7))という式を評価する時には4回別のコンビネーションにルールを適用することになる。コンビネーションをツリーで表現すると、このプロセスは図1.1のようになる。各コンビネーションをノード(接点)とそこから広がるブランチ(枝)で表現していて、ノードはオペレータかオペランドに対応している。終端ノード(派生するブランチがないノード)はオペレータか数値である。ツリーを使って評価を見ると、水が湧き上がるように、オペランドの値が終端から上の階層のコンビネーションへとのぼっていくようなイメージになる。階層的な、ツリーっぽいオブジェクトを扱うには、再帰はとても強力なオブジェクトであることが分かるだろう。この「値が湧き上がる」ようなイメージはツリーアキュムレーション(tree accumulation)(ツリーに溜め込む)の良い例として知られている。
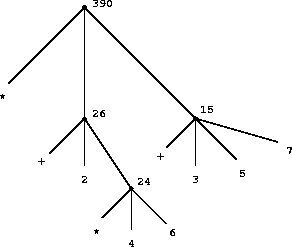
図1.1 コンビネーションの値をツリーで表していったもの
次の話、第一の規則
- 1. コンビネーションの中の部分的な式を評価していく を繰り返すと、評価する必要のない、コンビネーションでもないもの、数字とか組み込みのオペレータとかその他……にぶつかる。そんなときは基本的にはこうするよ、と規定する。
- 値が数字だったらそのまま数値として扱う
- 値が組み込みのオペレータだったら対応するマシンの命令として扱う
- 値がその他のものだったらその環境で名前と結び付けられた値して扱う
で、 + とか * とかをグローバル環境でマシン命令と結び付けられたシンボルだと考えれば、2つ目のルールは3つ目のルールの特別な場合だとみなせる。ここでのキーポイントは式のなかのシンボルが何を意味するかを決定する時の、環境が果たす役割だ。Lispのような対話的な言語ではきっちりと環境を決めないで (+ x 1) のような式について色々言うのは無意味だ。ちゃんとシンボルx(とかシンボル+とか)の環境を明確にしよう。3章で書くんだけど、環境っていうのは評価をおこなうときの文法みたいなものなのだ。この考えはプログラムの実行について理解する上で重要。
注意、上の規則は定義に関することは扱わない。例えば (define x 3) を評価してもそれは define を引数 x と 3 に作用させることにはならなくて、ただ x と 3 を結びつけることにしかならない。(だから (define x 3) はコンビネーションじゃない)
こういう式をスペシャルフォームという。 (define x 3) は今までに出てきた唯一の例外だ。だけど他のもすぐ出てくる。スペシャルフォームはそれぞれ独自のルールで評価をおこなう。こういう色々なルールを持った式でプログラミング言語の文法はできている。でも他の言語と比べて、Lispの文法はシンプルだ。シンプルな「一般的なルール」とちょっとの「スペシャルフォーム」でできている。(*7)
1.1.4 プロシージャの合成
Lispには強力な言語に備わっているべき要素があるのを見てきた。確認してみよう、
- 数値はプリミティブなデータで、数学的な演算子(+, -, *, /など)はプロシージャである。
- コンビネーションのネストは命令を結合する方法である。
- defineをつかって名前と値を結びつけるのは、抽象化のひとつの方法である。
これから、もっとパワフルな抽象化の手法であるプロシージャの定義について学ぶ。これにより「命令の結合」というか命令のかたまりに名前を付け、ひとつのユニットとして参照できるようになる。
はじめに「二乗」の表し方について考えてみよう。我々の自然言語では「何かを二乗するには、二乗したいものに同じものをかければいい」という。これを「我々の言語」で言うとこうなる。
(define (square x) (* x x))これでsquare(二乗)という名前の手続きの合成ができた。こいつはローカルな名前 x をつかって「二乗したいものに同じものをかける」をあらわしている。 x はちょうど、自然言語での代名詞のような役割を果たす。定義を評価するとこのプロシージャのかたまりがつくられ、squareという名前が与えられる。
一般的な定義はこう、
(define (<name> <formal parameters>) <body>)(define (<名前> <パラメータ>) <本体>)<name> がシンボルで、環境においてプロシージャの定義と結び付けられる。(*8) <formal parameters> は本体で使う名前を定義すると同時にそのプロシージャへの引数を受け取る。(訳注:なんかへん。プロシージャへの引数に名前を付ける的な理解でいいと思う) <body> ではパラメタが実際の引数の値に置き換えられて、このプロシージャの式が返す値を産む(yield)というか返す。 <name> と <formal parameters> はひとつのかっこで囲まれている、これは呼び出す時の形式と同じになっている。
squareを定義した。だからこれを使える
>(square 21)
441
>(square (+ 2 5))
49
>(square (square 3))
81squareを他のプロシージャを組み立てるためのブロックとしてつかうこともできる。例えば、x^2+y^2(xの二乗+yの二乗)はこう表す。
(+ (square x) (square y))そして、今なら簡単に。 sum-of-square (二乗の和)というプロシージャを定義することができる。
(define (sum-of-squares x y)
(+ (square x) (square y)))>(sum-of-squares 3 4)
25さらに sum-of-square をべつのプロシージャのためのブロックとしてつかえる
(define (f a)
(sum-of-squares (+ a 1) (* a 2)))>(f 5)
136合成して名前をつけられたプロシージャはプリミティブなプロシージャと同じように扱うことができる。実に、 sum-of-square の定義を見ただけじゃ、squareが+とか*みたいにインタプリタに組み込まれているのか、プロシージャの合成として定義されているのか分からない。
1.1.5 プロシージャを作用させるときの置換モデル
オペレータが合成プロシージャであるコンビネーションを評価する時でも、インタプリタはプリミティブなプロシージャのときと同じプロセスに従い動作する。1.1.3で説明したように、インタプリタはコンビネーションの各要素を評価し、プロシージャを引数に作用させるるのだ。
プリミティブなプロシージャを引数に作用させる仕組みがインタプリタに組み込まれているとする。合成プロシージャについて作用されていくプロセスは以下のようになる。
- 合成プロシージャを引数に作用させるには、プロシージャの本体を評価し、各パラメータを対応する引数で置換していく。
このプロセスの説明のため、以下のコンビネーションを評価してみよう
(f 5)このfは1.1.4で定義されたプロシージャだ。まず、fの本体をみてみる
(sum-of-squares (+ a 1) (* a 2))パラメータを引数である5で置換する
(sum-of-squares (+ 5 1) (* 5 2))こうして問題は2つのオペランドと1つのオペレータsum-of-squaresを持つコンビネーションの評価に還元された。このコンビネーションを評価することはさらに3つの細かな問題となる。プロシージャを作用させるためにオペレータを評価しなければならないし、引数を得るためにオペランドを評価しなければならない。そして今、(+ 5 1)は6となり、(* 5 2)は10となる。だから、6と10にプロシージャsum-of-squareを作用させるのだ。これらの値はsum-of-squareの本体部のパラメータxとyの代わりとなり、式は以下のように還元される。
(+ (square 6) (square 10))squareを定義してあれば、さらに還元され
(+ (* 6 6) (* 10 10))掛け算され
(+ 36 100)最後には
136今説明したプロセスはプロシージャを作用させるときの置換モデルである。
