|
//#pragma comment(linker, "/SUBSYSTEM:WINDOWS /ENTRY:mainCRTStartup")
#include <GL/freeglut/freeglut.h>
#include <math.h>
#include <stdio.h>
#define PI 3.1415926
#define WIDTH 320
#define HEIGHT 240
#define SX sin(2*PI*rotate_x/360.0f)
#define SY sin(2*PI*rotate_y/360.0f)
#define SZ sin(2*PI*rotate_z/360.0f)
#define CX cos(2*PI*rotate_x/360.0f)
#define CY cos(2*PI*rotate_y/360.0f)
#define CZ cos(2*PI*rotate_z/360.0f)
//マトリクス構造体
struct MATRIX {
union {
struct {
float _11, _12, _13, _14;
float _21, _22, _23, _24;
float _31, _32, _33, _34;
float _41, _42, _43, _44;
};
float mat_4x4[4][4];
float mat_16[16];
};
MATRIX(){//単位行列に初期化
INIT();
}
void INIT(){
for(int i=0;i<16;i++){
this->mat_16[i]=0;
}
this->_11=this->_22=this->_33=this->_44=1;
}
void PRINT(char* text){
printf("%s\n%f,%f,%f,%f\n%f,%f,%f,%f\n%f,%f,%f,%f\n%f,%f,%f,%f\n\n",
text,
this->_11,this->_21,this->_31,this->_41,
this->_12,this->_22,this->_32,this->_42,
this->_13,this->_23,this->_33,this->_43,
this->_14,this->_24,this->_34,this->_44);
}
void Efficient_Synthesize(float pos_x,float pos_y,float pos_z,float
rotate_x,float rotate_y,float rotate_z,float scale_x,float scale_y,float
scale_z){
this->_11=(CY*CZ)*scale_x;
this->_12=(CY*SZ)*scale_x;
this->_13=-SY*scale_x;
this->_14=0;
this->_21=((SX*SY*CZ)-(CX*SZ))*scale_y;
this->_22=((SX*SY*SZ)+(CX*CZ))*scale_y;
this->_23=(SX*CY)*scale_y;
this->_24=0;
this->_31=((CX*SY*CZ)+(SX*SZ))*scale_z;
this->_32=((CX*SY*SZ)-(SX*CZ))*scale_z;
this->_33=(CX*CY)*scale_z;
this->_34=0;
this->_41=pos_x;
this->_42=pos_y;
this->_43=pos_z;
this->_44=1;
}
};
MATRIX mat;
void display(void)
{
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glViewport(0, 0, WIDTH, HEIGHT);
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
//視野角,アスペクト比(ウィンドウの幅/高さ),描画する範囲(最も近い距離,最も遠い距離)
gluPerspective(30.0, (double)WIDTH / (double)HEIGHT, 1.0, 1000.0);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glTranslatef(12.0f,55.0f,-90.0f);
glRotatef(50.0f,0.0f,0.0f,1.0f);
glRotatef(50.0f,0.0f,1.0f,0.0f);
glRotatef(50.0f,1.0f,0.0f,0.0f);
glScalef(5.0f,3.0f,9.0f);
glGetFloatv(GL_MODELVIEW_MATRIX,&mat.mat_16[0]);
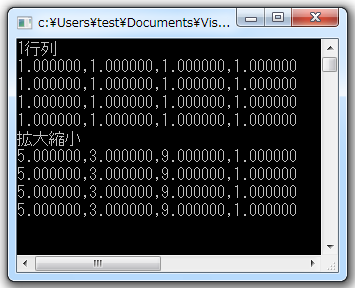
mat.PRINT("各種アフィン変換で合成行列作成");
glLoadIdentity();
mat.INIT();
mat.Efficient_Synthesize(12.0f,55.0f,-90.0f,50.0f,50.0f,50.0f,5.0f,3.0f,9.0f);
mat.PRINT("効率のよい合成で同じ結果になるか?");
getchar();
glutSwapBuffers();
}
void idle(void)
{
glutPostRedisplay();
}
void Init(){
glClearColor(0.3f, 0.3f, 0.3f, 1.0f);
}
int main(int argc, char *argv[])
{
glutInitWindowPosition(100, 100);
glutInitWindowSize(10, 10);
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_RGBA | GLUT_DOUBLE);
glutCreateWindow("効率の良い合成");
glutDisplayFunc(display);
glutIdleFunc(idle);
Init();
glutMainLoop();
return 0;
}
|